TVM AutoTVM 多 GPU 加速 Tuning
场景 双 NVIDIA 1080Ti, Linux 服务器
需求 AutoTVM 的 Tuning 可以让两张 CUDA 显卡同时运行模型 (AMD 的没试过)
过程
当前场景为 tuner 和 runner 都跑在同一台机器上的情况 如果需要一台跑 tuner,一台跑 runner,请配置好 tracker 和 server 的 IP tracker 和 server 都可以放在有显卡的机器里
- 首先查看一下 GPU 的 id,你可以通过这条命令来查看:
nvidia-smi -L
比如我这里输出的是 0 和 1:
(base) admin@deeplearning:~$ nvidia-smi -L
GPU 0: GeForce GTX 1080 Ti (UUID: GPU-a4602aba-35cb-97cd-ef5a-f7d12aabdc88)
GPU 1: GeForce GTX 1080 Ti (UUID: GPU-92deed64-3b37-f0a4-1095-40f0f596d64b)
- 用 screen 创建 1 个 rpc_tracker
screen -S tvm_tune_tracker
python -m tvm.exec.rpc_tracker --host=0.0.0.0 --port=9190
输入完之后,如果 tracker 运行成功,那就按下 CTRL+A 然后按下 CTRL+D,detach 当前的 screen
- 用 screen 创建 2 个 rpc_server(因为我有 2 个 GPU)
还记得第一步查看的 GPU id 吗?下面的 `CUDA_VISIBLE_DEVICES`` 就要设置成刚才看的 GPU 的 id
screen -S tvm_tune_server0
export CUDA_VISIBLE_DEVICES=0
python -m tvm.exec.rpc_server --tracker=127.0.0.1:9190 --key=1080ti
## 输入完之后,如果 server0 运行成功,那就按下 CTRL+A 然后按下 CTRL+D,detach 当前的 screen
screen -S tvm_tune_server1
export CUDA_VISIBLE_DEVICES=1
python -m tvm.exec.rpc_server --tracker=127.0.0.1:9190 --key=1080ti
## 输入完之后,如果 server1 运行成功,那就按下 CTRL+A 然后按下 CTRL+D,detach 当前的 screen
注意,上面的 export 是重点!
如果在 shell 里直接不写 export ,直接写 CUDA_VISIBLE_DEVICES=0 是无效的!!!!
尽管不写 export 时,echo $CUDA_VISIBLE_DEVICES 也会输出 1,但是实际上并没有设置环境变量。
原因是 autotvm 会通过 python 的 os.environ['CUDA_VISIBLE_DEVICES'] 的值来决定使用哪一个 id 的 GPU。
#
检测效果
按照官方教程修改 device 为 1080ti,ip 地址和端口记得也要按照自己的实际情况进行修改,然后运行 tune_relay_cuda.py
Extract tasks 之后,你应该可以通过 nvidia-smi 看到 GPU 的利用情况:
watch -n 0.5 nvidia-smi (意思是每隔 0.5s 运行 nvidia-smi 命令一次)
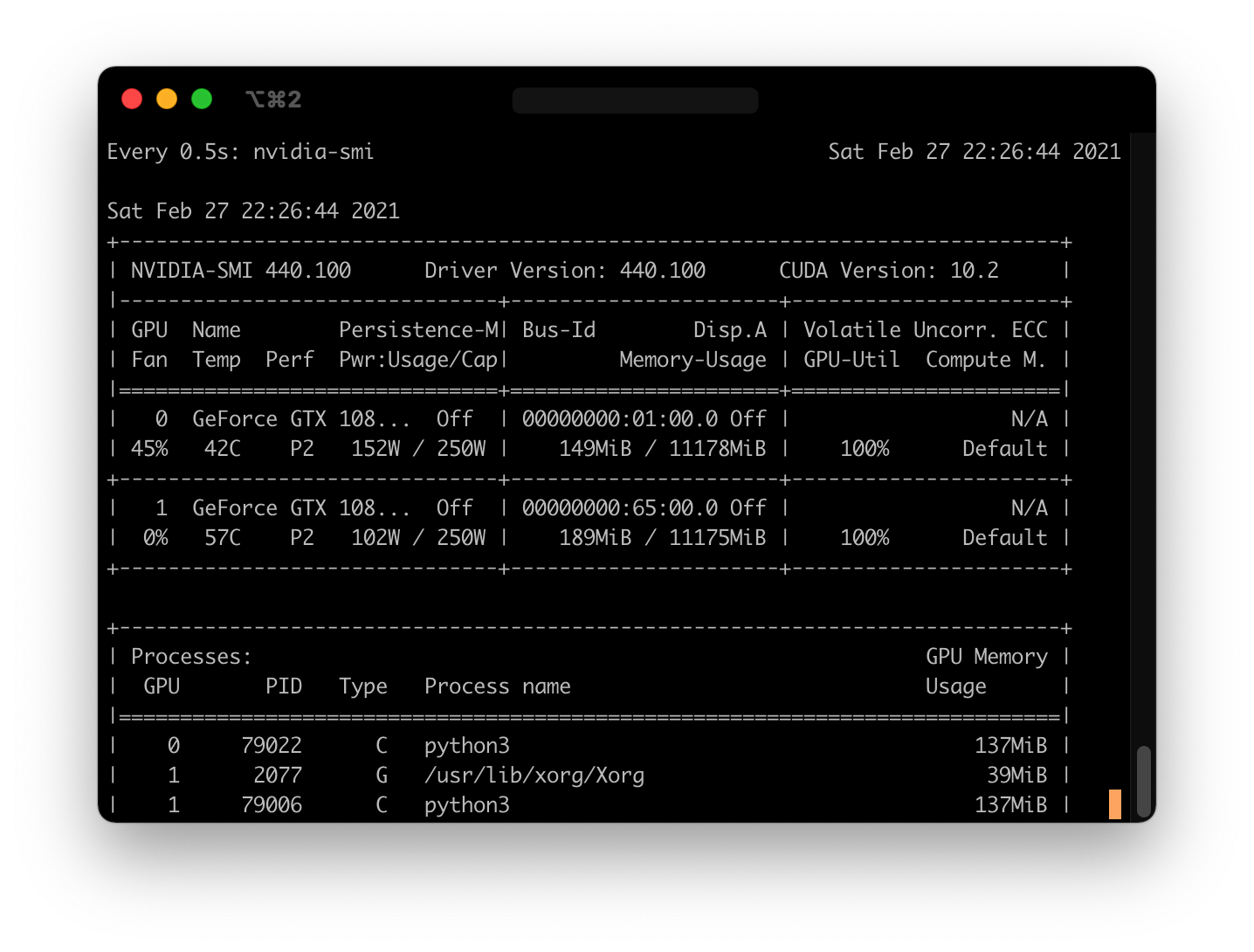
可以看到两张显卡都已经利用起来了。
– END –
#
2023年8月23日 补充
看到自己之前写的文章,感觉好幼稚啊哈哈哈哈