拆穿 introl 和 ainewshub,TPU 比 GPU 便宜 4 倍是 AI 编的幻觉
- EN
- ZH-CN
Table of Contents
声明:这篇文章不是要论证 TPU 不如 GPU。TPU 和 GPU 各有适用场景,谁强谁弱要看具体负载。我要说的是,目前网上流传的那批对比数据本身不准确,很多是 AI 编造、无法溯源的。下面拆的就是这些假数据。
Artificial Analysis 最近放出一组硬件基准测试1,以 Llama 3.3 70B、vLLM、每查询 30 output tokens/s 的参考速度计算每百万输入输出 token 的成本,NVIDIA 对 TPU v6e (Trillium) 有大约 5 倍的每美元 token 优势,对 AMD MI300X 有大约 2 倍优势2。

Artificial Analysis 在 X 上公布的硬件基准结论,NVIDIA 对 TPU v6e 有约 5 倍每美元 token 优势,对 MI300X 约 2 倍,H100 是 1.06 美元,MI300X 是 2.24 美元,TPU v6e 是 5.13 美元。
跟这些能复现的数据一起在网上传的,还有另一类东西。
#
一篇高调的对比文
introl 有一篇文章,标题叫 Google TPU v6e vs GPU: 4x Better AI Performance Per Dollar3。核心论点是 TPU 每美元性能比 H100 好 4 倍,TPU 在推理经济性上全面压过 NVIDIA。它的关键数据来自另一篇文章,ainewshub.org 的 Nvidia vs Google TPU 2025 Cost Comparison4。顺着这条引用链往下看,会发现两篇都是 AI 生成的,数据是编的。
#
锤点一,核心引用指向一份不存在的数据
ainewshub 那篇最核心的一句话是这样写的。

ainewshub 文章里的核心论断,4.7 倍每美元性能,来源标的却是并不存在的 MLPerf v4.1 LLM 推理结果。
“4.7× better performance-per-dollar on LLM inference than Nvidia H100/H200”,来源标的是 Google Cloud MLPerf Inference v4.1 results + customer case studies, October 2025。
但其实,MLPerf Inference v4.1 里,Google 的 TPU 提交项只有 stable-diffusion-xl 一个模型。我去 MLCommons 的官方结果5里按 Google 加 TPU 筛,v4.1 Closed Datacenter 下只有两条记录,tpu-v5e-4 和 tpu-v6-4,跑的都是 stable-diffusion-xl。
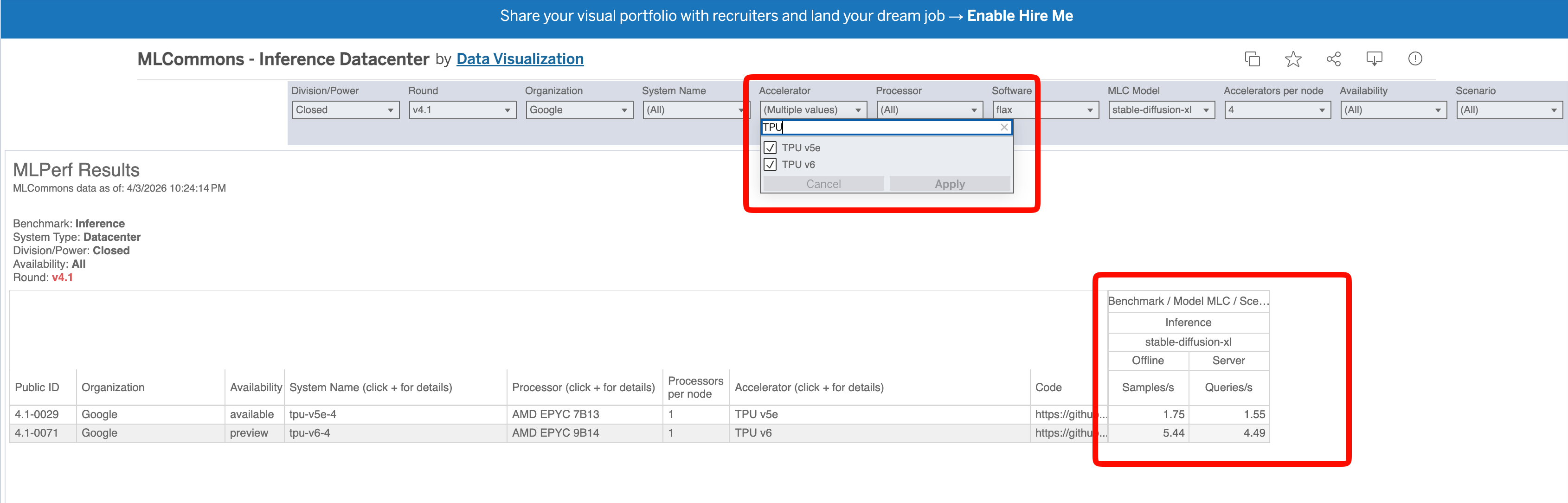
在 MLPerf v4.1 Closed Datacenter 里筛 Google TPU,只有 tpu-v5e-4 和 tpu-v6-4 两条,跑的都是 stable-diffusion-xl,没有任何 LLM 推理项。
没有任何 LLM 推理项!这篇文章引用的所谓 MLPerf v4.1 的 LLM 推理每美元性能 4.7 倍,在它声称的来源里根本不存在。数字是凭空生成的,然后挂了一个看起来权威的出处。
其次,MLPerf 压根不报每美元性能。它报的是吞吐,samples/s 和 queries/s,里面没有价格。所以那 4.7 倍根本不可能是从 MLPerf 算出来的。
#
锤点二,数字在转载之间漂移
把 introl3 和 ainewshub4 两篇放一起时,数字对不上(而且有虚假陈述)。
- 每美元性能倍数,introl 写 4 倍,ainewshub 写 4.7 倍。(这条纯骗人,见上文)
- MLPerf 版本,introl 引 v3.1,ainewshub 引 v4.1。(不知道 introl 从哪哪来的数据)
- Midjourney 案例,introl 写月支出从 200 万美元降到 70 万美元,ainewshub 写从 210 万美元降到 70 万美元。(这条我没仔细核查,大概率也是幻觉出来的)
转载来转载去,每复述一次就变一点。他妈的,模型每生成一次,就重编一个差不多的数出来。
#
锤点三,精确到吓人的 TCO 表,却没有来源
ainewshub4 给了一张三年总拥有成本表,1000 芯片集群,NVIDIA H100 总成本 1.77 亿美元,Google TPU v6 总成本 7850 万美元,省 9850 万美元。还细分到硬件降 48%、电费降 66%、制冷降 67%、支持降 63%、网络降 67%、地产降 63%。(全是编的)
这种精确到个位百分比的分项拆解看起来很专业。问题是没有一项能溯源。配套的客户案例也一样,Midjourney,还有一家所谓 C 轮计算机视觉创业公司月支出从 34 万美元降到 8.9 万美元,全是无法核实的具体数字。
#
最可恶的是 “data verified”
顺着 ainewshub 那篇成本对比文再往上游追,它的来源指向同一个站点的另一篇文章,AI Inference Costs: TPU vs GPU 20256。同样的数字在这里又复述了一遍,4 倍性价比、Midjourney 省 65%、TPU v5e 在 9 项里赢 8 项,我必须再次强调,这个数据是假的、是不存在的。
它结尾那句声明是这样写的:
Data verified as of November 26, 2025. Sources include Google Cloud documentation, MLPerf benchmarks, company earnings reports, and verified industry migrations.
根本没有核实。
它说核实了,却给不出任何一个能点开的链接,没有具体报告,没有方法。前面已经查过,它依赖的 MLPerf TPU LLM 推理结果根本不存在。所谓 verified,全是假的。
同一个站点的不同文章,连这些假数字都对不上,写的人自己也不知道这个数从哪来,因为它本来就不存在。
一个成批生产幻觉数字、再统一盖上 data verified … 这个垃圾网站真害人不浅
#
目前我查到的数据是这样(至少比他们网站可信一点)
Artificial Analysis 的 System Load Test1,跑的是 Llama 3.3 70B。
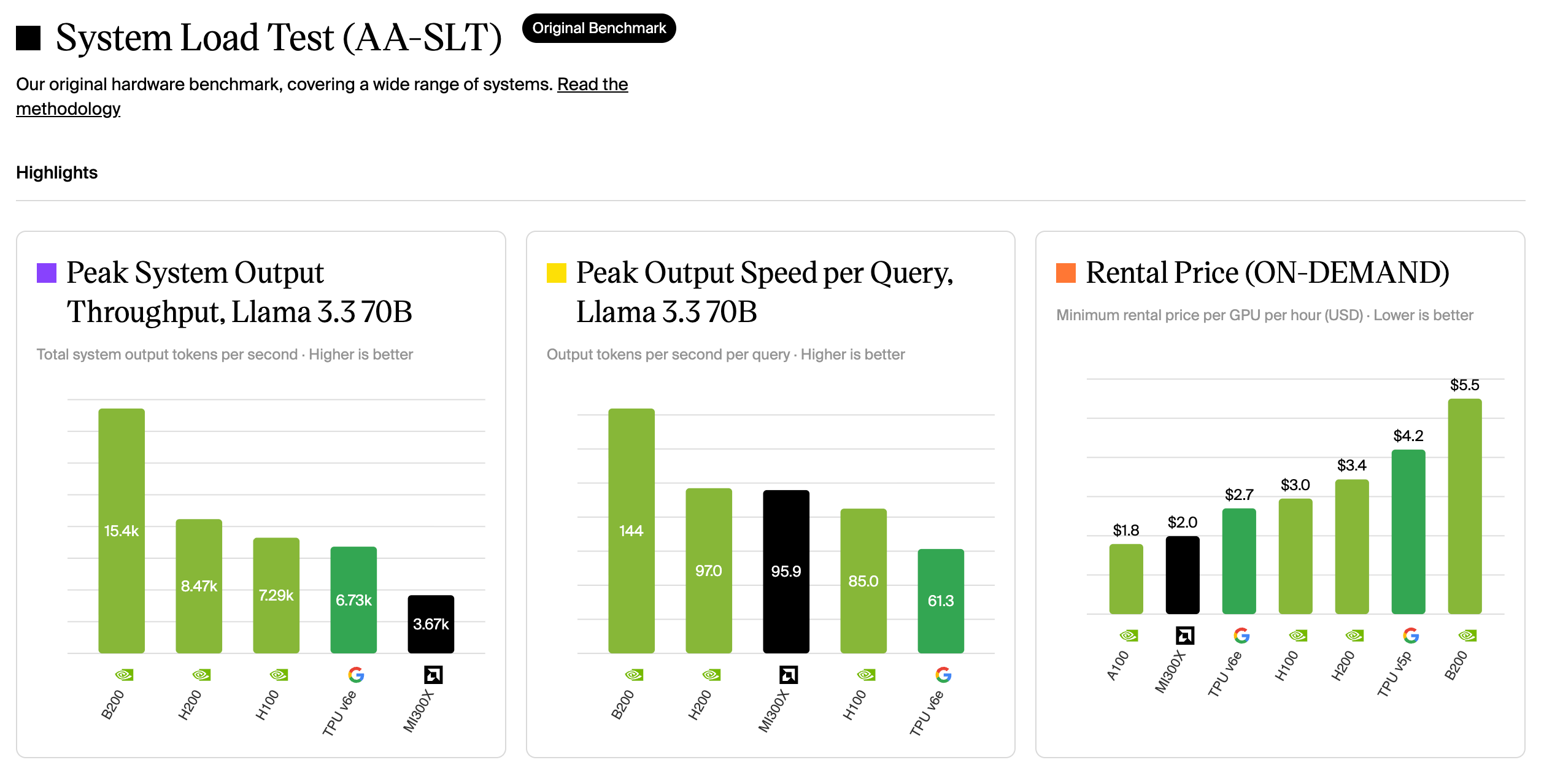
Artificial Analysis System Load Test,Llama 3.3 70B 的峰值系统吞吐、每查询输出速度和按需租用价格。
峰值系统吞吐,B200 是 15.4k tokens/s,H200 是 8.47k,H100 是 7.28k,TPU v6e 是 6.73k,MI300X 是 3.67k。TPU v6e 落在 NVIDIA 同代后面。每查询输出速度,TPU v6e 是 61.3 tokens/s,是这组里最慢的。
成本要分两种情况说,这里 TPU 也有能算的账。
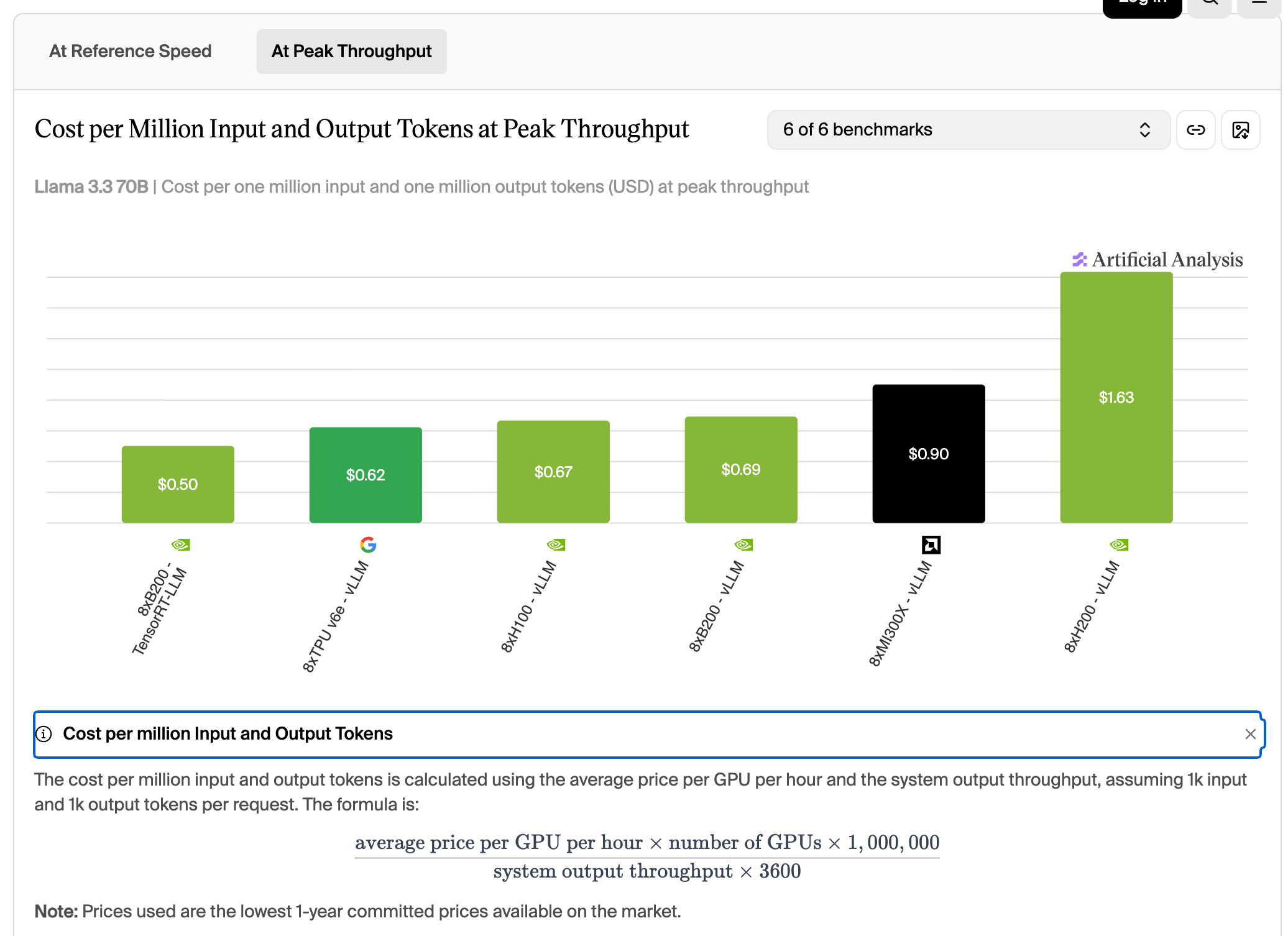
Llama 3.3 70B 在峰值吞吐下的每百万 token 成本,TPU v6e 为 0.62 美元,与 H100 的 0.67 到 0.69 美元接近。
在峰值吞吐下算每百万 token 成本,TPU v6e 是 0.62 美元,和 H100 的 0.67 到 0.69 美元接近,比 MI300X 的 0.90 美元和 B200 跑 vLLM 的 1.63 美元都便宜。如果负载是离线大批量、能把芯片喂满,TPU 的账是划算的。
但线上服务很少跑在峰值吞吐上。一旦要求一个能用的交互速度,比如每查询 30 tokens/s 的参考速度,TPU v6e 的单位成本就跳到 5.13 美元,而 H100 是 1.06 美元。这就是 Artificial Analysis 说的大约 5 倍差距的来处。
后面我们会自己进行 benchmark 得到一手数据,到时再对比。
#
识别出 AI 生成垃圾文的方法
只要遵循一个原则:任何数据、任何数字,必须有可点开的来源,必须有可复现的方法。