Distributed System: Primary Backup Replication
Table of Contents
开胃菜来了!
你有一个硬盘,存了很多重要资料,你担心这个硬盘某天坏了,怎么办?
当然是多买点硬盘,把数据备份在不同的硬盘上。
保证可靠,就是通过多个一致的数据副本来实现的。
#
前提假设
我们假设所有的操作都是确定的
#
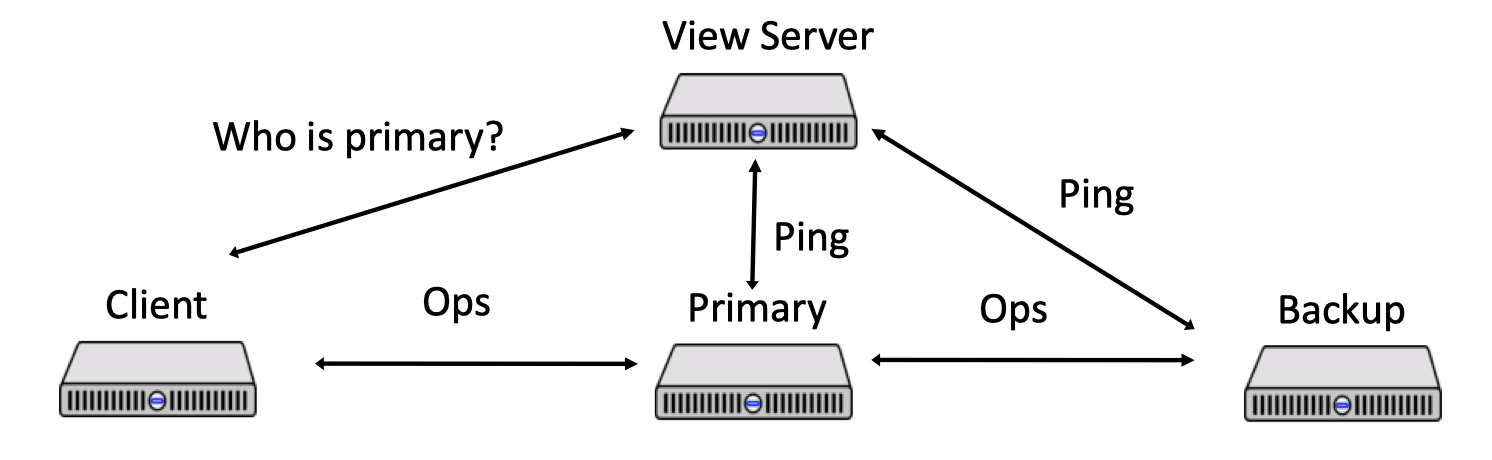
最简单的 primary & backup
- clients 发送 operation (Put, Get, Append) 到 primary-server
- primary-server 决定 operation 的执行顺序
- primary-server 把 operation 的执行顺序发送给 backup-server
- backup-server 按照 primary-server 发送的顺序执行 operation(hot-standby)
- 或者 backup-server 按照 primary-server 发送的顺序记录 operation 但不执行(cold-standby)
- 等 backup-server 成功结束,primary-server 给 client 发回复
问题是,怎么决定谁来当 primary-server?
怎么决定谁来当 backup-server?
client 怎么知道谁是 primary-server?
答案: 引入一台 view-server,让这个 view-server 来做决定,并且 client 去问 view-server 谁是 primary-server。为什么叫它 view-server?因为这涉及到一个重要概念「view」,后面会讲到,别着急!
知道了答案,我们可以这样设计整个系统:
我们让每台服务器发送心跳给 view-server,告诉 view-server 自己还活着。
问:有没有可能自己活着但是 view-server 认为自己死了? 有可能因为网络问题,心跳没发出去,view-server 认为节点挂了,但其实节点还活着
我们 promote idle-server 成为 backup-server,但不越级 promote 成为 primary-server
问:除非有种情况?系统刚启动时(全都是 idle-server、需要一个 primary 的时候)
只有 backup-server 会被 promote 成 primary-server
#
什么是 view-server 里的 view
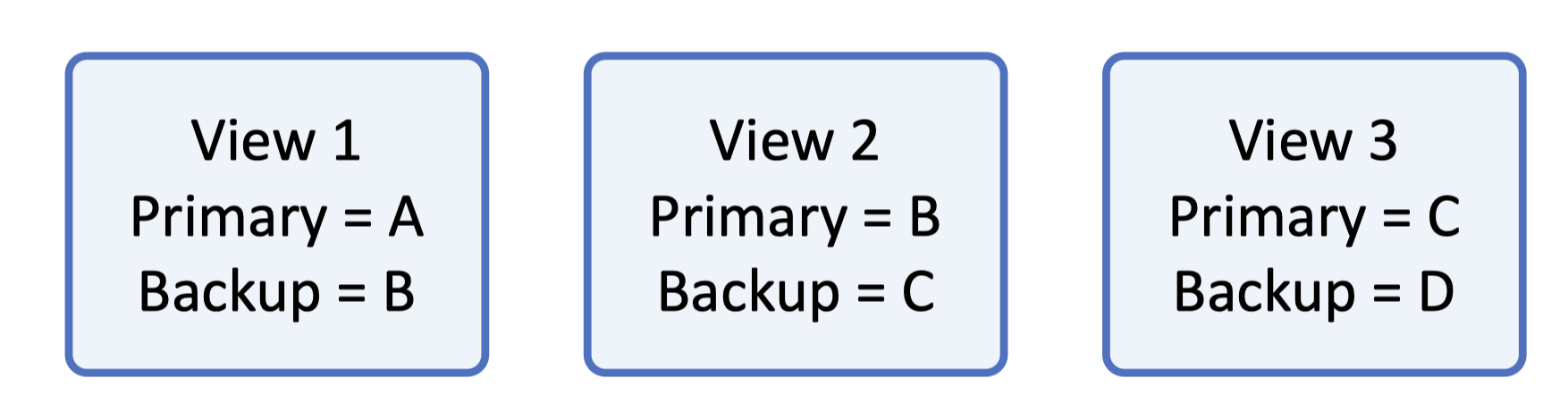
一个 view 是一个 primary-server 和一个 backup-server 的集合,描述了当前状态谁是 primary 谁是 backup。
注意,一个 view 里,只有一个 primary 和一个 backup,其它的 server 标记为 idle。(想想看为什么这样设计?)
view 由 view-server 进行管理,其他节点可以获取到当前系统的 view。
看了上面的描述,感觉自己又行了,于是我设计出了下面的流程
系统刚开始,挑一个 primary-server,然后挑一个 backup-server,其它的都是 idle-server,然后开始工作。
primary 立马让 backup 成为新的 primary,从 idle 里面挑一个成为 backup,然后让这个新的 primary 把状态都发送给 backup
很简单嘛!这能有什么问题?
话音刚落,问题就来了。
请看下面这个情况:
`View 1, primary=A, backup=B;` 这时候 A 挂了,B 成为 primary,从 idle 里面挑一个 C 成为 backup,然后 B 发送状态给 C。
`View 2, primary=B, backup=C;` B 发状态的时候挂了,C 成为 primary,idle 里面没机器了
`View 3, primary=C, backup=_;` C:😅?(此时 C 根本不知道系统的状态是什么)
所以我们刚刚对整个系统的描述,是有缺陷的。
怎么改呢,我们让 view-server 必须等待 primary-server 确认 当前的 view。
就算 primary-server 挂了,view-server 也要等 ACK。
(直觉告诉我们,这种等待 ACK 的行为可能导致系统卡住)
#
总结一下所有的规则
在 view i+1 的 primary 必须是 view i 的 backup
如果没有这个规则会怎样?Split brain: primary A, backup B, but can’t reach view-server. C,D are promoted to primary and backup, C doesn’t know previous state.
primary 必须等 backup 执行完,才可以回复 client
如果没有这个规则会怎样?Missing write: client writes to A,A crashes before writing to B, clients read from B
一定要转发 read() 给 backup 吗?(这是一个常见的优化操作)必须转发。不然可能出现 Stale read: at view 1, A,B are primary and backup, but A cannot reach view-server. now view 2, B,C are primary backup. client 1 writes to B, client 2 reads from A. A returns outdated data(不过 stale read 依然符合 sequential consistency)
如果 view 是正确的,backup 必须接受转发的请求,并且执行
如果没有这个规则会怎样?Partially Split Brain
non-primary 节点必须拒绝 client 的请求
如果没有这个规则会怎样?Inconsistencies: client’s view may outdated, send request to old primary server.
state-transfer 的时候不能有操作。(Atomic State Transfer)
如果没有这个规则会怎样?
#
脑裂 (Split-brain)
这个词有点吓人。。。其实是在说:在网络故障时,两个及以上的节点都认为自己是 Leader (primary-server)。
View 1, primary=A, backup=B; 这时候 A 网络出故障无法连接到 view-server,B 成为新的 primary。 View 2, primary=B, backup=_; B 是 新的 primary,但 A 也认为自己是 primary
在我们之前的规定里,只有 primary-server 会回复 client,但是脑裂的时候,两个节点都会回复 client,这就可能导致 client 收到的数据不一致。 (破坏了 Linearzability)
#
系统卡住
有哪些可能导致系统卡住(处理不了 client 的请求)的情况?
- view-server 挂了
- 整个网络挂了
- client 只能练到 view-server,不能连接到 primary-server
- backup server 没有了(因为 primary 转移状态给 backup,转移完了回复 view-server 一个 ACK)
- 状态转移之前 primary 挂了
#
重复写入
#
为什么 Primary Backup 比较难
- primary 可能挂掉
- backup 可能挂掉
- 通讯可能 临时/永久 挂掉
- 参与者的决策可能存在延迟:
- view server 不知道 primary 挂了
- primary 挂了吗?挂了之后恢复,还需要回复 client 吗?
- backup 挂了吗?state transfer 结束了吗?
- client 不知道 view 有没有切换
#
总结一下 view-server 的缺点
- view-server 自己存在单点故障问题
- view-server 必须等待 primary 的 ack,即使 primary 可能挂了也要等
#
状态机复制
状态机有一个特性: 任何初始状态一样的状态机,如果执行的命令序列一样,则最终达到的状态也一样。
如果将此特性应用在多参与者进行协商共识上,可以理解为系统中存在多个具有完全相同的状态机(参与者),这些状态机能最终保持一致的关键就是起始状态完全一致和执行命令序列完全一致。
根据状态机的特性,要让多台机器的最终状态一致,只要确保它们的初始状态是一致的,并且接收到的操作指令序列也是一致的即可,无论这个操作指令是新增、修改、删除抑或是其他任何可能的程序行为,都可以理解为要将一连串的操作日志正确地广播给各个分布式节点。
我们并不要求所有节点的每一条指令都是同时开始、同步完成的,只要求在此期间的内部状态不能被外部观察到,且当操作指令序列执行完毕时,所有节点的最终的状态是一致的,这种模型就被称为状态机复制(State Machine Replication)。
#
Tips
实现 Paxos 的注意事项可以参考 Junhui 的 Cheatsheet1
#
Reference
https://jzhu.xyz/posts/paxos (Cheatsheet of MultiPaxos Impl) ↩︎